Can AI tell if I'm writing AI slop? A machine learning journey


Sometime around ChatGPT's initial release, everyone decided that Machine Learning (ML) is also going to be called "AI" now. It's high time I learned a little bit more about creating machine learning models, so I thought it would be fun to make one trained on all my writing to see if it can distinguish between my actual writing vs LLM slop trying to sound like me.
I've never done this before! This is how I did it.
Success Criteria
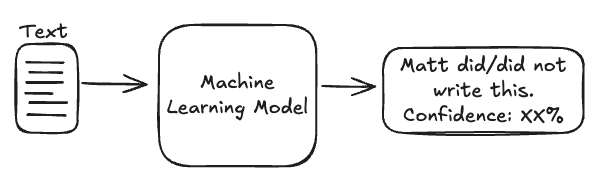
At the end of this experiment, I want to input some text into a model, which will then output "Yes you wrote that" or "No you didn't write that" with a confidence score.
Data Gathering
The most important part of creating a good ML model is gathering good data. I've written a lot of stuff in my life, but this website is the best and latest example of all my writing in my own voice. Yes, this site is 99% written by a human! (I use LLMs for typos, sue me)
With a local copy of my website, I launched Claude Code in its root directory and asked it to extract all the post contents and convert it to markdown. After some massaging (removing pictures, deleting lists of restaurants, etc), this resulted in a 182KB file of 43 blog posts (not including this one). It's not a ton, but hopefully it's enough. Typically with machine learning, the more the better (depending... I'll get into that later).
Now what do I do with the data? I've been meaning to try out Databricks, since they're all about ingesting a bunch of your data to do all kinds of analytics, data engineering, etc. Fortunately, it looks like they have a free trial, so I took it for a spin. I have no idea what the free account limitations are, and who knows what a Databricks Unit is, but I can't imagine I'll do anything that will break the bank. They don't require a credit card, so who cares!
I never hit any kind of rate limit while playing with this free account. I was even able to use their LLM assistant without complaint. I'm curious which model it's using, because it would respond quicker than API calls to ChatGPT or AWS Bedrock. Something self-hosted? Makes sense from a cost perspective, and maybe part of the reason DataBricks prints money.
Getting Data In
I've never used Databricks before, but I poked around the interface and pretty quickly noticed UI elements that rhymed with Snowflake and BigQuery. Ingesting terabytes of data into these platforms every day can be painful since you need to properly label, categorize, and limit access to it. It's critical, necessary work with entire teams devoted to it. Fortunately, I don't need to worry about wrangling mountains of data for this project, and I was able to just upload my markdown file into a data volume.
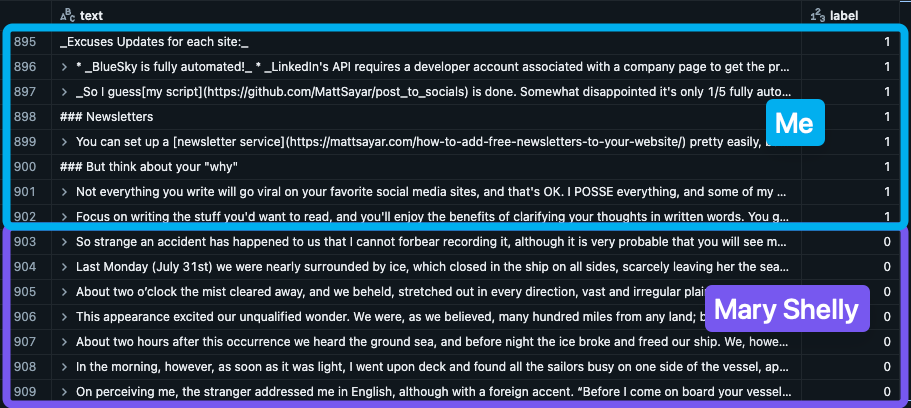
For an ML model to accurately predict whether or not a sample of writing is mine or not, it needs my writing (already uploaded) AND it needs samples of writing that's NOT mine for contrast. Initially, I used the first chapter of Mary Shelly's Frankenstein from Project Gutenberg as a good "not me" sample. I easily uploaded that .txt file as well.
Training the Model
At this point, I played around with the UI enough to sorta figure out what I needed to do, but I was at the point where I asked myself, "What now?" I turned to Claude for help [transcript]. The best part about LLMs is even when they're wrong, they keep you from being completely stuck. Even though Claude got some stuff wrong (it listed some incorrect links/buttons, I uploaded/parsed my data differently, tweaked the training code in the notebooks, etc.) it still pulled me out of the "what now?" state. And once I was developing in the Databricks UI, there was a built-in AI assistant panel like Cursor or Windsurf.
As I was setting up the notebook, I noticed that my markdown file had too much markdown formatting (see below). I don't natively write markdown, so I used Claude Code again to parse out just the wordy contents of my blog, and remove all the links and formatting.
This process really reinforces the value of good training data. Garbage in, garbage out!
The meat of training the model was a short block in the Notebook. You split your data into training and testing sets, then create a scikit-learn pipeline, with MLflow tracking and logging the results. I'll be honest, there's a lot of black box stuff happening here to me, but my understanding is that the pipeline is taking the training sets, converting them into friendly vector formats, and tuning weights in the chosen model type and testing them to ensure accuracy.
This training step didn't take long, about a minute, but after it was done I could finally test it myself! This is what it looked like when I tried inputting the opening lines of Moby Dick into the model:
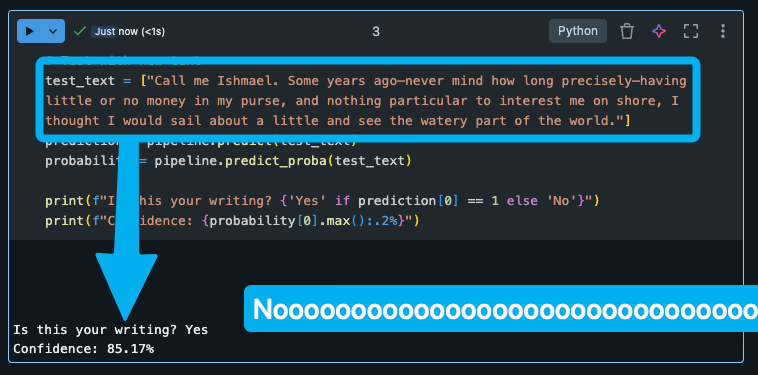
Any piece of text I put in there, it said I wrote it. The confidence varied, but I hit another, "What now?" wall. The built-in GenAI assistant suggested using a different ML model (LogisticRegression), and that I should "consider using more diverse 'other' writing samples."
More samples sounded like a good idea, because if the training dataset is heavy with just my writing, it makes sense that it would think everything is my writing. Sorry Mary Shelly, I need more than just 5KB of Frankenstein.
My next thought was to match the size of my writing samples kilobyte for kilobyte with "other" samples. I found a dataset of thousands of IMDB reviews, which represents a diverse set of writing styles and opinions. I made Claude Code compile a 182KB .txt file for me.
Unfortunately, even after uploading, parsing, and retraining with that data, testing still says everything I inputted was written by me. Logically, it kinda makes sense that if half the writing in this training set is from me, the model will be biased to think half of all writing is me. I need more data! Fortunately, that IMDB data set contains 50MB worth of reviews, so I dwarfed my writing samples with it.
Training took a little longer (several minutes) because I increased the training set by a couple orders of magnitude. This didn't bother me, since I'm running all this for free, and beggars can't be choosers. Once it was finished, I tried the Moby Dick sample again aaaand:
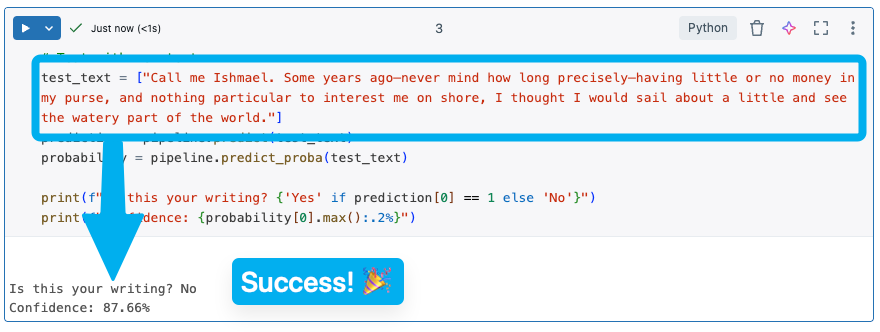
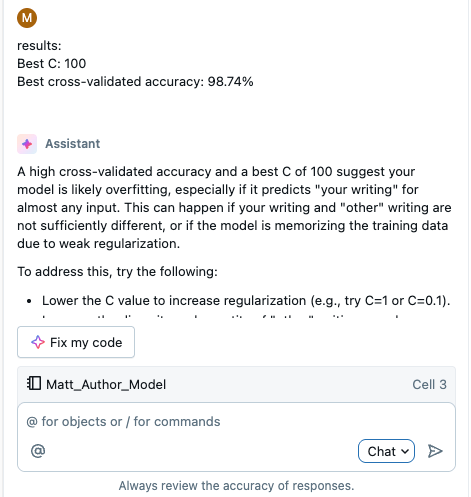
...at least I thought it was a success. But after running a few more tests, I realized I had the opposite problem: everything I put in there came back NEGATIVE.
Faced with another, "What now?" situation, the Databricks AI assistant suggested I tune a specific parameter (C) in the training. It was able to run a quick test to find the optimal value based on the training/test sets, and now it works pretty well!
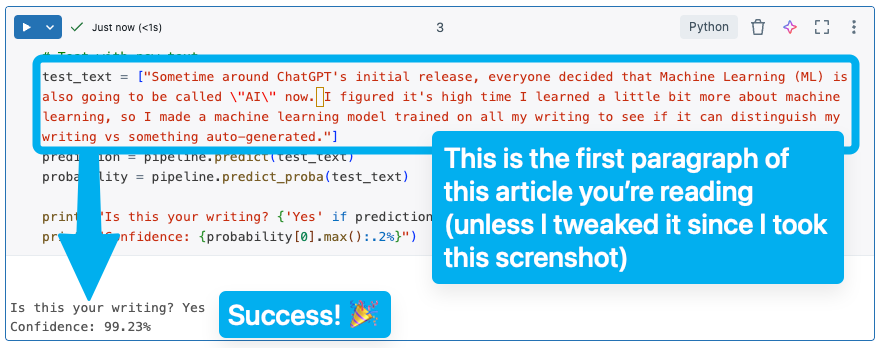
I did a bunch of ad hoc testing (my text messages, stuff from random blogs, posts from Hacker News comments) and it's pretty good! Most of the time it's correct with a high confidence. Sometimes it's wrong with a low confidence. That's what confusion matrices are all about.
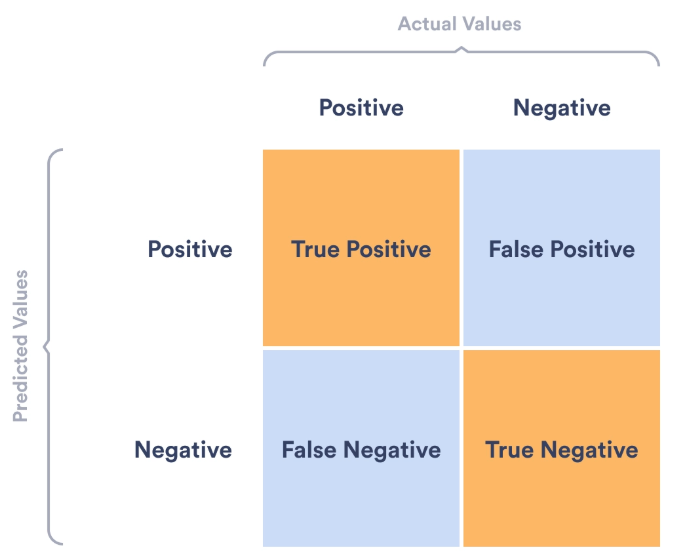
Ideally, at this point I would run some automated tests to make sure everything is in the yellow quadrants. Depending on the use case, you'll want it to be correct >99% of the time (eg for cybersecurity detection efficacy). In this use case, that's likely not achievable without a lot lot lot more of my writing samples.
Can it detect AI slop?
Using ChatGPT 5 Thinking, I told it to use my website to try and copy my writing style.
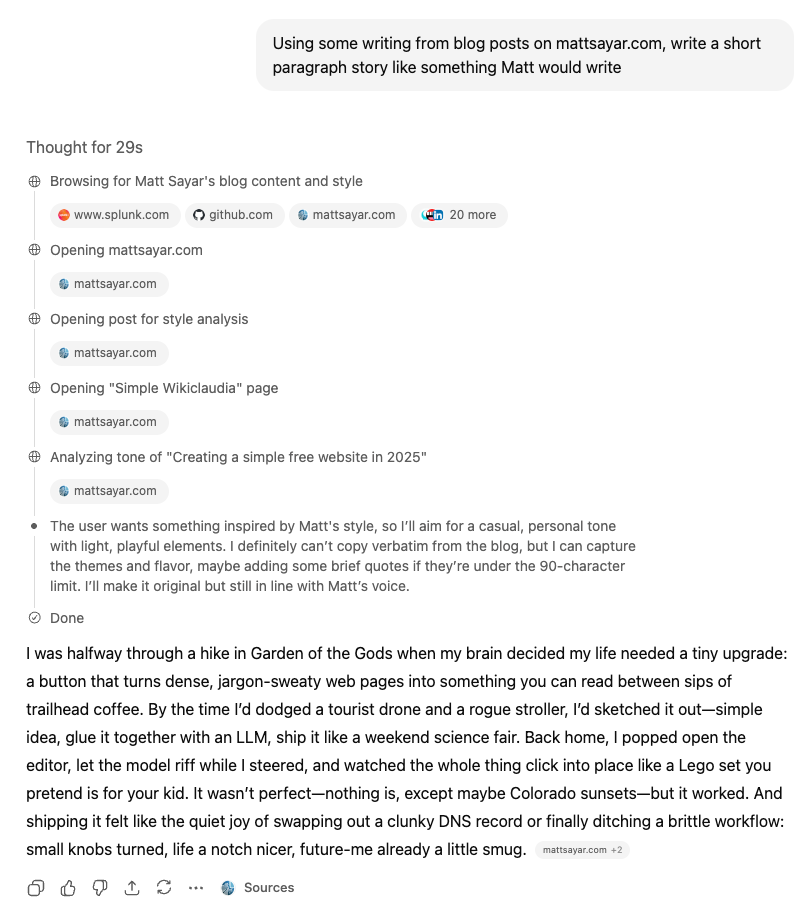
Did it fool my machine learning model?
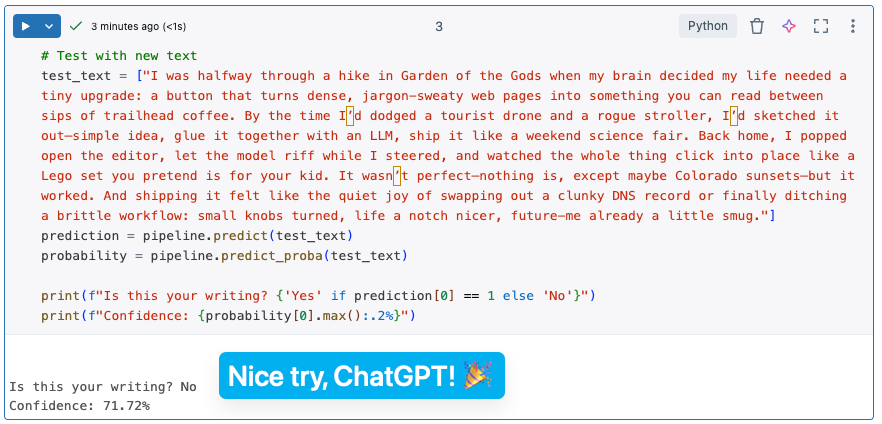
It did not! Low-ish confidence, but as one element in a verification analysis, I'm pretty happy with that. Just don't tell my boss this machine learning model exists so he doesn't start scrutinizing all my emails...
Model training is somewhat of an art
Small changes to tuning parameters, tweaking input data, and changing model types to increase efficacy helps a LOT, and it shows that model training is partially an art (but still mostly science). Large language models like ChatGPT go through a similar process of data gathering, model training, and testing, and this process clearly shows why Claude is different from GPT-5 is different from Gemini etc.
To make them actually GOOD sounds really challenging, and is probably why those teams get paid the big bucks. I liken it to developing video games: anyone can create a simulator with characters who walk and jump and collect coins, but making them FUN is hard.
So what's next?
In the real world, an ML model would undergo a LOT more testing, tuning, tweaking. Then, it would get deployed so you can actually use it without copy/pasting text in a Notebook. But I don't want to because it's the weekend, and I just wanted to do this as a proof of concept to learn more about ML. Plus, I'm not gonna pay for you to try undermining my writing.
But this is just the beginning for real machine model use cases. For example, as I write more, that new literature could be auto-ingested into the data set over time to retrain the model. That would increase the confidence and accuracy of the detection. Then it would get retested, validated, and deployed on a schedule. It's a whole lifecycle that needs constant updates to be as effective as possible.
It was kinda fun to build my own machine learning model. It was great having LLM assistance when I got stuck. This reminds me of a quote from GitHub's CEO about the increased ambition you get with LLMs:
Developers rarely mentioned “time saved” as the core benefit of working in this new way with agents. They were all about increasing ambition. We believe that means that we should update how we talk about (and measure) success when using these tools...
You should also read:
It's Time to Tell Time Again
I updated the clock game to be a little harder. Previously, it just accounted for fifteen minute increments. Now, it does five-minute increments. You can find all these in my toy-code repo. That previous post won't be affected by this update because I've started using…
Continue reading...Just pick a Static Site Generator and start writing
Ever since I put my website together, it's been humming along by publishing content with Publii. Overall I really like it, but I'm not a seasoned expert on the pros and cons of all the different static site generators (SSGs). It looks like Publii isn't…
Continue reading...Writing Toy Code with ChatGPT is a Blast
In trying to teach my son how to better understand Left vs Right, I did some searching for a quick little game that can help him hone his skills faster. I found something close to what I was looking for, but not quite. That game focuses…
Continue reading...